- Início
- Log TV
- Agenda
- Artigos
- Notícias
- Entrevistas
- Log Content
- Especiais
- Revistas
- Supply Chain Insights
- América Latina

Prevendo e compreendendo a rotatividade de motoristas de caminhão de longa distância usando dados operacionais do motorista e classificadores de machine learning supervisionados

- machine learning supervisionado
- rotatividade de funcionários
- motoristas de caminhão
1. Introdução
Toda cadeia de suprimentos no mundo depende, em algum momento, do transporte rodoviário para facilitar a movimentação de mercadorias. Só nos Estados Unidos, o transporte rodoviário de mercadorias é uma indústria de aproximadamente US$ 800 bilhões que emprega quase 3,5 milhões de motoristas profissionais (CSCMP, 2022). E, no entanto, a indústria enfrenta um problema crônico e não resolvido: uma rotatividade muito elevada de caminhoneiros — em muitos casos superior a 100% (LeMay et al., 2009; Miller et al., 2021, 2020, 2013). Nos últimos anos, à medida que as cadeias de suprimentos em todo o mundo passaram por crises, este problema tornou-se ainda mais evidente, especialmente para as empresas que gerem esta rotação agitada de motoristas de caminhão empregados.
Este artigo adota uma abordagem única para esta importante questão ao (1) investigar o potencial dos dados de condução operacional recentemente disponíveis para revelar padrões anteriormente não observados na utilização de motoristas de caminhão; e (2) aproveitar esses padrões para prever eventos individuais de rotatividade de caminhoneiros antes que eles aconteçam, o que poderia dar às empresas de transporte rodoviário oportunidades novas e valiosas para intervir e reter os condutores em risco de saída.
Nossos dados vêm de uma fonte até então inexplorada na pesquisa acadêmica sobre rotatividade de motoristas, os Dispositivos Eletrônicos de Registro (da sigla em inglês ELDs). Em 2017, os Estados Unidos promulgaram um novo mandato que exigiu que todos os caminhoneiros americanos registrassem eletronicamente as suas horas de trabalho a partir de 2019. Este sistema substituiu os registros em papel que eram anteriormente utilizados. A digitalização destes dados criou conjuntos de dados muito grandes que permitiram novos conhecimentos sobre as condições de trabalho do caminhoneiro norte-americano. Treinamos três algoritmos de classificação (regressão logística, florestas aleatórias e máquinas de vetores de suporte) em dados de 1.298 motoristas únicos observados ao longo de três anos para testar se, quando organizados de acordo com padrões semanais de utilização, esses dados recém-disponíveis poderiam prever a rotatividade de motoristas de caminhão no nível do motorista individual.
Abordar esse problema de uma nova maneira adiciona uma perspectiva única e valor. Como apontado recentemente nesta publicação, a satisfação dos motoristas de caminhão no emprego é crítica para a gestão efetiva da cadeia de suprimentos (Khaitan et al., 2022). Os questionários são a ferramenta mais comumente empregada para medir a satisfação dos motoristas de caminhão no emprego e intenção de se demitir. No entanto, pesquisadores notaram que questionários frequentemente não são práticos e têm custos proibitivos na prática empresarial real (Khaitan et al., 2022). Em segundo lugar, pesquisadores notaram que os antecedentes de eventos de rotatividade nem sempre são adequados aos pressupostos da regressão de mínimos quadrados e da análise de coeficientes (Huang & Kechadi, 2013; Suzuki et al., 2009). Por esses motivos, estamos utilizando novos dados de trabalho operacional, que as empresas são agora obrigadas por lei a recolher, e classificadores de machine learning, que são capazes de explorar padrões e relações não-lineares nesses dados, a fim de fazer previsões de rotatividade.
A seção 2 deste estudo apresenta uma visão geral de trabalhos anteriores sobre a questão da rotatividade de motoristas, quase todos eles baseados em questionários (veja a Tabela 1). A seção 3 apresenta os dados utilizados nesta análise. Dois experimentos de classificação são usados como base, e seus resultados, apresentados nas seções 4 e 5. As conclusões e aplicações de gestão são discutidas na seção 6.
2. Trabalhos relacionados
Uma motivação frequente para a investigação acadêmica de motoristas de caminhão é a taxa de rotatividade de funcionários infamemente alta da indústria. A maioria dos estudos publicados na imprensa acadêmica e comercial reportam que a rotatividade de caminhoneiros ao nível da empresa excede 100% ao ano (LeMay et al., 2009; Miller et al., 2021, 2013). As conclusões de trabalhos anteriores sobre a identificação do que leva os caminhoneiros a deixar os seus empregos e a contribuição deste artigo para o fluxo de investigação sobre a rotatividade de caminhoneiros estão resumidas abaixo.
Numa análise fatorial dos dados de pesquisas da indústria de transporte rodoviário, Min e Lambert classificaram 12 fatores que afetam a retenção de motoristas de caminhão e os relataram em ordem decrescente de importância. Os três primeiros incluíram (1) remuneração competitiva; (2) idade do equipamento; e (3) reputação da empresa (Min e Lambert, 2002). Esta importância primária da retenção de salários para motoristas de caminhão também foi confirmada em vários estudos subsequentes, incluindo Belzer e Sedo (2018), Garver et al. (2008), Johnson et al. (2011), Keller (2002), LeMay et al. (2009), Phares e Balthrop (2022) e Williams et al. (2011). Também sabemos, pelo trabalho cuidadoso de LeMay, Williams e Carver, que o que importa para a retenção de motoristas de caminhão varia de acordo com a idade e a experiência do motorista. Sua pesquisa descobriu que os novos motoristas priorizavam taxas salariais mais altas do que os motoristas experientes. Em vez disso, os motoristas experientes priorizaram a liberdade de fazer seus próprios horários (LeMay et al., 2009).
Mas outros fatores também são importantes para a retenção de caminhoneiros. O tempo fora de casa dos motoristas também tem sido consistentemente documentado como um antecedente importante da rotatividade (Burks e Monaco, 2019; Corsi e Fanara, 1988; Keller, 2002; Williams et al., 2011). No entanto, a maioria dos motoristas de caminhão americanos são pagos apenas por milha carregada percorrida, então eles obviamente também querem passar algum tempo dirigindo na estrada. Essa compensação entre o tempo livre em casa e o tempo remunerado gasto dirigindo é um equilíbrio em que a administração pode errar. Dois estudos anteriores ajudam-nos a compreender esta difícil escolha. Primeiro, De Croon descobriu que semanas de trabalho excessivamente longas estavam correlacionadas com a insatisfação dos motoristas de caminhão (De Croon et al., 2004). Burks e Monaco acrescentaram um corolário interessante num estudo que identificou que a discrepância entre quantas horas um motorista planejava conduzir naquela semana, e quantas horas realmente trabalhou, é também um importante determinante da satisfação no trabalho (Burks e Monaco, 2019). Ainda mais especificamente, Suzuki, Patsuch e Crum identificaram uma distinção importante entre dias de semana e fins de semana nas expectativas de horas de condução dos condutores. No seu estudo, mais horas de condução por semana correlacionaram-se com uma maior satisfação no trabalho e, portanto, com uma menor probabilidade de desistir. No entanto, as cargas de fim de semana inferiores a 700 milhas inverteram esta relação e aumentaram a probabilidade de alguns caminhoneiros desistirem – provavelmente porque essas viagens curtas não eram muito lucrativas e, portanto, uma troca de tempo em casa que não valia a pena (Suzuki et al., 2009).
2.1. Contribuição deste artigo para a literatura
Este artigo faz duas contribuições únicas para a pesquisa em rotatividade de motoristas de caminhão. Primeiro, ao invés das abordagens baseadas em questionários mais frequentemente publicadas, usamos novos dados operacionais, dados de ELDs, que capturam as experiências de trabalho reais dos motoristas com registros eletrônicos com data e hora. Nossa abordagem baseada em ELDs nos permite olhar para os ciclos de utilização do dia da semana do motorista como novos antecedentes para eventos de rotatividade de motoristas. Isto tem um significado especial na prática porque, conforme exigido por lei, estes dados de ELDs já estão sendo recolhidos por empresas de transporte rodoviário, ao passo que os dados dos questionários podem ser proibitivamente dispendiosos e onerosos de executar (Khaitan et al., 2022). Em segundo lugar, construímos preditores avançados de rotatividade de motoristas no nível de motorista individual usando regressão logística, florestas aleatórias e máquinas de vetores de suporte, que, até onde sabemos, não foram aplicadas anteriormente na rotatividade de funcionários acadêmicos ou na literatura de sistemas de previsão especializados relacionados a motoristas de caminhão.
3. Dados
Os dados de ELDs foram fornecidos por uma empresa de transporte rodoviário americana de médio porte (aproximadamente 1.500 caminhões no total). Os dados foram fornecidos para quatro períodos separados de 8 semanas, começando em Setembro de 2016 e terminando em Agosto de 2018 (ver Tabela 2). Cada um dos 4 conjuntos (‘‘T1’’–‘‘T4’’) abrange, portanto, conjuntos distintos, mas sobrepostos, de condutores de caminhões. Os conjuntos de dados foram limpos para: (1) incluir apenas motoristas solitários de longa distância, o que significa motoristas que viajam longas distâncias para seu trabalho e trabalham sozinhos. Esta é a subcategoria de motoristas mais impactada pela escassez de motoristas nos Estados Unidos (American Trucking Association, 2021). Os dados de ELDs são registros de trabalho com data e hora, no qual o motorista deve escolher em um menu de possíveis atividades de trabalho ou fora de serviço para cada hora do dia. Como a direção é de interesse aqui, os dados também foram limpos para remover entradas de registro de trabalho onde foram relatadas horas de condução impossíveis ou ilegais. Os motoristas de caminhão americanos estão limitados a um máximo de 11 horas de condução por dia (FMCSA, 2022). Excluímos entradas que excedessem esse total de 11 horas de condução. Essa limpeza resultou em 1.298 motoristas únicos de longa distância com conjuntos de dados limpos e completos que foram considerados nesta análise.
Os ELDs exigem que os motoristas atribuam seu tempo a uma das quatro categorias principais: Dirigindo, Em serviço sem Dirigir, Fora de serviço e Beliche (FMCSA, 2023). Com base na nossa leitura da literatura, optamos por focar nos dois status de trabalho ‘‘Dirigindo’’, que é o tempo gasto efetivamente dirigindo o caminhão; e ‘‘Em serviço sem dirigir’’, que inclui, entre outras coisas, o tempo gasto esperando para ser carregado e descarregado. "Dirigindo", é claro, determina o salário líquido que esses motoristas recebem, porque, nos EUA, os motoristas de caminhão são pagos por milha rodada. ‘‘Em serviço, sem dirigir’’ inclui o tempo de espera dos motoristas para serem carregados e descarregados nos expedidores e destinatários, que os resultados da pesquisa mostram que é frustrante para os motoristas. Organizamos esses pontos de dados em médias diárias gastas dirigindo (“Dirigindo”) e gastando trabalhando, mas não dirigindo (“Em serviço”). Os resumos dessas medidas em todos os quatro períodos são apresentados na Figura 1 e na Tabela 3.
4. Metodologia
4.1. Técnicas de modelagem
Três algoritmos classificadores foram aplicados para prever eventos de rotatividade de motoristas com base na média diária de cada motorista e no desvio padrão do tempo gasto dirigindo e do status de serviço. Esses classificadores incluem regressão logística, florestas aleatórias e máquinas de vetores de suporte. É claro que muitos outros algoritmos candidatos existem e foram aplicados a estudos de rotatividade, incluindo recentemente nesta revista "General regression neural network (GRNN), Extreme Learning Machines (ELM) and Con- volutional neural networks (CNN)" em Davoodi et al. (2023). Da mesma forma, "K-means clustering" em Huang e Kechadi (2013). No entanto, como apontado em Verbeke et al. (2011), ao modelar a rotatividade, a engenharia de recursos pode, na verdade, ser mais importante do que a seleção do classificador ao se esforçar para construir e compreender sistemas de previsão especializados aplicados. Por esse motivo, optamos por usar três classificadores diferentes como um teste robusto do poder preditivo dos recursos de média e desvio padrão do dia da semana que projetamos a partir dos dados do dispositivo de registro eletrônico dos motoristas.
4.1.1. Regressão logística
O classificador de regressão logística adapta a regressão linear clássica ao caso de variáveis dependentes discretas. Ou seja, ao invés de estimar o valor de uma variável independente contínua (y), o modelo de regressão logística estima a probabilidade de uma observação pertencer a um conjunto finito de classes. Nesta aplicação, as duas classes possíveis são os motoristas que permaneceram na empresa (codificados ‘‘0’’) e os que não permaneceram (codificados ‘‘1’’). Tal como representado de forma semelhante em Bertsimas et al. (2016) e Huang e Kechadi (2013), a probabilidade de uma observação i pertencente à classe 1 é dada pela função de resposta logística:
onde P(y= 1) indica a probabilidade de classificação 1, e ????0 e ???????? representam a interceptação e a inclinação da função do registro de probabilidades, respectivamente.
Tabela 1
Visão geral selecionada da literatura anterior em rotatividade de motoristas de caminhão.
|
Autor(es) |
Título e revista |
Ano |
Antecedentes da demissão identificados |
Método |
|
Min e Lambert |
Truck driver shortage revisited - Transportation journal |
2002 |
Condições de trabalho, desenvolvimento de carreira, fatores monetários |
Análise de questionário |
|
Keller |
Driver relationships with customers and driver turnover - Journal of business logistics |
2002 |
Pagamento, tempo em casa, relacionamento com expedidor, relacionamentos com clientes |
Análise de questionário |
|
Garver e Williams |
Employing latent class regression analysis to examine logistics theory: An application of truck driver retention - Journal of business logistics |
2008 |
Pagamento, relacionamento com expedidor, relacionamento com a gerência |
Análise de questionário |
|
Lemay, Willams, Carver |
A Triadic view of truck driver satisfaction - Journal of transportation management |
2009 |
Motoristas mais velhos querem mais liberdade, motoristas mais novos querem pagamentos mais altos |
Análise de questionário |
|
Suzuki, Crum, e Pautsch |
Predicting truck driver turnover - Transportation research part E |
2009 |
Horas dirigindo, dados demográficos do motorista, relacionamentos com expedidores |
Dados operacionais e modelo de sobrevivência |
|
Johnson, Bristo, McClure e Schneider |
Determinants of job satisfaction among long-distance truck drivers - International journal of management |
2011 |
Tempo fora de casa, pagamento, falta de respeito dos embarcadores |
Entrevistas |
|
Williams, Garver e Taylor |
Understanding truck driver need-based segments: Creating a strategy for retention - Journal of business logistics |
2011 |
Pagamento, segurança pessoal, tempo em casa, equipamento, avanço na carreira, carga de trabalho, relação com expedidor |
Análise de questionário |
|
Lemay e Williams |
The causes of truck driver intent-to-quit: A best-fit regression - Int’l journal of commerce and management |
2013 |
Responsividade dos expedidores |
Questionário |
|
Prockl, Teller, Kotzan e Angell |
Antecedents of truck drivers’ job satisfaction and retention proneness - Journal of business logistics |
2017 |
Apoio não-financeiro dos empregadores importa mais que apoio financeiro |
Análise de questionário |
|
Belzer e Sedo |
Why do long-distance truck drivers work extremely long hours? - The economic and labor relations review |
2018 |
Motoristas querem dirigir mais horas até atingirem uma meta de renda |
Análise de questionário |
|
Burks e Monaco |
Is the US labor market for truck drivers broken? - Monthly labor review |
2019 |
A diferença entre horas de trabalho esperadas e horas reais trabalhadas |
Análise de questionário do governo |
|
Phares e Balthrop |
Investigating the role of competing wage opportunities in truck driver occupational choice - Journal of business Logistics |
2022 |
Aumentos de salário ajudam na retenção, mas devem superar os aumentos concorrentes em ocupações industriais concorrentes |
Análise econométrica |
Tabela 2
Períodos de tempo e observações dos dados não tratados.
|
Período |
Experimento |
Datas |
Motoristas únicos |
Motoristas mantidos |
Motoristas rotacionados |
|
T1 |
E1 |
18/09/16 a 12/11/16 |
786 |
- |
281 (36%) |
|
T2 |
E2 |
19/02/17 a 15/04/17 |
763 |
482 (63%) |
- |
|
T3 |
E3 |
04/03/18 a 28/04/18 |
512 |
- |
158 (31%) |
|
T4 |
E4 |
24/06/18 a 18/08/18 |
556 |
398 (72%) |
- |
Tabela 3
Estatísticas resumidas de horas de condução para todos os períodos de tempo.
|
Estatística |
Segundas-feiras |
Terças-feiras |
Quartas-feiras |
Quintas-feiras |
Sextas-feiras |
Sábados |
Domingos |
|
Média de horas de condução Desvio padrão |
6.25 1.71 |
7.06 1.44 |
7.28 1.39 |
7.23 1.36 |
6.95 1.42 |
6.73 1.67 |
6.26 1.98 |
|
Média de horas em serviço Desvio padrão |
1.43 1.61 |
1.47 1.59 |
1.43 1.53 |
1.14 1.21 |
1.16 1.33 |
1.09 1.70 |
1.04 1.76 |
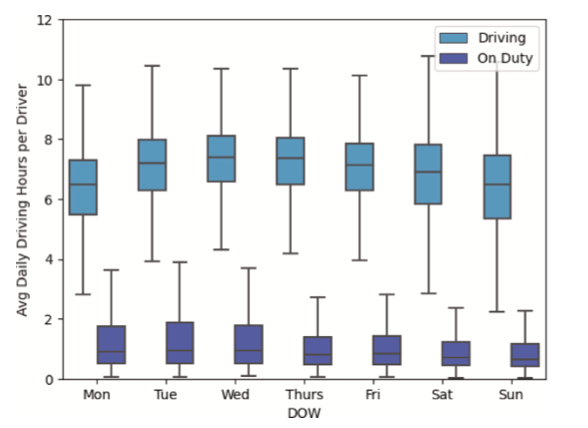
Fig. 1. Resumo da média de horas dirigindo por dia da semana em todos os períodos de tempo.
4.1.2. Florestas aleatórias
O classificador de floresta aleatória é um classificador de conjunto baseado em árvore (Breiman, 2001; Cutler et al., 2012). Baseia-se na intuição dos classificadores de árvores de decisão, aplicando um grande número de árvores de decisão, cada uma treinada em um subconjunto de dados disponíveis. O classificador de floresta aleatória coleta então o voto de cada árvore de decisão na classificação correta de uma observação com base no subconjunto de variáveis independentes nas quais a árvore individual foi treinada (Bertsimas et al., 2016). Os votos são computados a partir da “floresta” de árvores de decisão treinadas e uma classificação é feita. Um breve pseudocódigo para o classificador de floresta aleatória é apresentado abaixo, baseado em Hastie et al. (2009).
Algoritmo 1: Floresta Aleatória para Classificação
1. Para b = 1 para B:
(a) Desenhe uma amostra bootstrap Z* de tamanho N a partir dos dados de treinamento.
(b) Cresça uma árvore de floresta aleatória T até os dados de bootstrap, repetindo as etapas a seguir para cada nó terminal da árvore, até que o tamanho mínimo do nó ???????????????? seja alcançado.
i. Selecione m variáveis aleatoriamente das p variáveis
ii. Escolha o melhor ponto de divisão variável entre os m
iii. Divida o nó em dois nós filhos
2. Produza o conjunto de árvores
Para fazer uma previsão em um novo ponto x:
Classificação: Seja a previsão de classe da b-ésima
árvore da floresta. Então
Adaptado de Hastie et al. 2009, p. 588.
4.1.3. Máquinas de vetores de suporte
O classificador de vetores de suporte atribui previsões de classe definindo um hiperplano multidimensional que separa observações de treinamento rotuladas em um espaço de recursos n-dimensional. O classificador essencialmente encontra os limites ou arestas do recurso de um hiperplano candidato que minimiza erros de classificação no conjunto de treinamento. Isto pode ser formulado como um problema de otimização convexa, apresentado por Hastie et al. (2009) em sua forma muito geral:
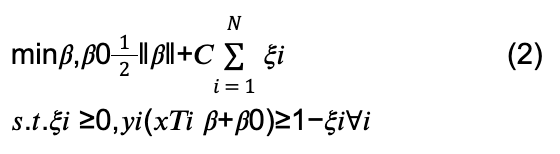
onde ???? é um vetor unitário ‖????‖ = 1; C representa um parâmetro de custo (essencialmente ∞ no caso linearmente separável); e ????1 , ????2 , ... , ???????? representam variáveis de folga.
4.2. Modelando fluxo de trabalho e processamento de dados
Os dados foram fornecidos à equipe de pesquisa em quatro períodos distintos de oito semanas ao longo de dois anos. É importante observar que a coleta de dados foi conduzida pela empresa independentemente de nossa influência ou projeto experimental. Exploramos a estrutura única do conjunto de dados para conduzir dois experimentos naturais. O Experimento 1 testa previsões para motoristas que aparecem no T1, mas não aparecem três meses depois no T2. A Experiência 1 continha um total de 782 motoristas, dos quais 281 desistiram (36%). O Experimento 2 testa previsões para motoristas que aparecem no T3, mas não aparecem 3 meses depois no T4. O Experimento 2 continha 512 motoristas, dos quais 158 entregaram antes do T4 (31%). O experimento T3 a T4 foi descartado devido ao intervalo muito maior entre os períodos de tempo (11 meses).
Cada algoritmo classificador foi treinado, ajustado e testado para cada experimento. Primeiro treinamos e ajustamos os algoritmos do classificador em um conjunto de treinamento/ajuste que compreende 60% dos dados disponíveis desse experimento. Usando validação cruzada de 5 vezes, ajustamos cada algoritmo do classificador para o conjunto de treinamento de cada experimento. Em seguida, testamos cada algoritmo classificador hiperajustado nos 40% reservados dos dados disponíveis de cada experimento. Esta abordagem é apresentada na Figura 2. As análises foram codificadas na linguagem de computação Python e fizeram uso da biblioteca de machine learning scikit-learn (Pedregosa et al., 2011) e do pacote de hiperajuste Optuna (Akiba et al., 2019). ).
4.2.1. Desempenho do modelo
São relatadas três medidas de desempenho do modelo, Área Sob a Curva (da sigla em inglês AUC), precisão e recuperação, assim como uma representação gráfica, Curva Característica do Operador do Receptor (da sigla em inglês ROC).
Seguindo a apresentação em Huang e Kechadi (2013), o desempenho dos algoritmos classificadores pode ser entendido com matrizes de confusão. A matriz de confusão apresenta contagens de classificações corretas e incorretas por classe. Consulte a Tabela 4.
Tabela 4
Exemplo de matriz de confusão para os experimentos 1 e 2.
|
Predição |
|||
|
Rotacionado |
Não-rotacionado |
||
|
Real |
Rotacionado Não-rotacionado |
????11 ????21 |
????12 ????22 |
4.2.2. Precisão e sensibilidade
A precisão refere-se à porcentagem de todas as classificações que estavam corretas. No contexto deste estudo, isso significaria a porcentagem de todos os motoristas que foram corretamente classificados como tendo sido desligados ou não. No contexto da Tabela 4, isso seria calculado como:
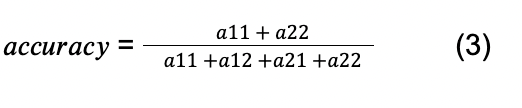
A sensibilidade é uma medida da probabilidade de prever uma classificação positiva, dado que tal classificação é realmente verdadeira. No contexto deste estudo, isto significa a probabilidade de prever um evento de rotatividade de motoristas, dado que o motorista realmente fez rotatividade. Verbeke et al. ressaltam que, no contexto da previsão de rotatividade, os custos associados a falsos positivos e falsos negativos não são iguais. É mais caro perder um verdadeiro positivo e perder a oportunidade de intervir. Por esta razão, a sensibilidade (por vezes chamada de ‘recall’) é uma medida de desempenho especialmente relevante (Verbeke et al., 2011). Dada a notação na Tabela 2, isso seria calculado como:
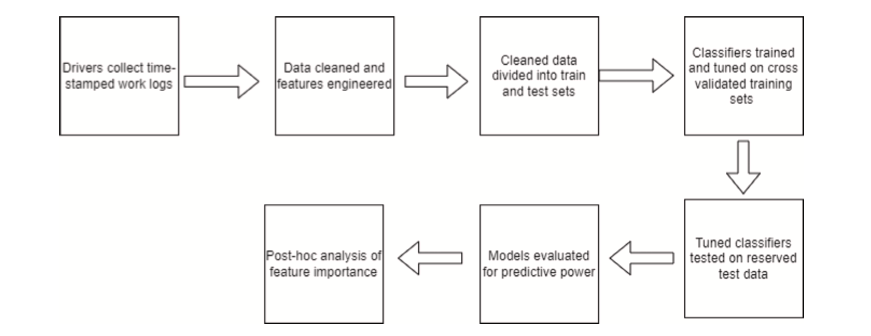
Fig 2. Diagrama esquemático do fluxo de trabalho para coleta de dados, engenharia de recursos, calibração e análise de modelo.
4.2.3. Curva Característica do Operador do Receptor (ROC)
Curvas características do operador do receptor (ROC) como as mostradas na Fig. 5 resumem o desempenho de um classificador. Com a taxa de verdadeiros positivos no eixo O???? e a taxa de falsos positivos no eixo O????, uma estimativa completamente aleatória teria uma chance de 50/50 de classificação correta (Bertsimas et al., 2016; Bradley, 1997). Nas curvas ROC nas Figs. 3 e 4, traçamos aquela linha de passeio aleatório 50/50 em traços cinza. Nesse sentido, então, um classificador plotado acima da linha de passeio aleatório na curva ROC prevê melhor do que uma estimativa aleatória.
4.2.4. Área sob a curva (AUC)
As informações apresentadas em uma curva ROC podem ser resumidas com uma estatística de Área Sob a Curva (AUC). Como o nome indica, AUC resume a área sob a linha ROC convexa. Pontuações mais altas na AUC implicam que o classificador é mais capaz de distinguir entre classes. Formalmente, a AUC pode ser calculada como:
onde ????0 é a soma das observações da classe 0, ????0 é o número de observações que pertencem à classe 0 e ????1 é o número de observações que pertencem à classe 1 (rotatividade). Esta explicação resume tratamentos semelhantes em Bradley (1997) e Huang e Kechadi (2013).
Tabela 5
Desempenho único do classificador em dados de teste nos experimentos 1 e 2.
|
Experimento |
Classificador |
AUC |
Precisão |
Sensibilidade |
|
E1 E1 E1 |
Regressão logística Floresta aleatória Máquina de vetores de suporte |
0.57 0.63 0.62 |
0.64 0.67 0.67 |
0.50 0.39 0.36 |
|
E2 E2 E2 |
Regressão logística Floresta aleatória Máquina de vetores de suporte |
0.56 0.63 0.61 |
0.68 0.69 0.69 |
0.56 0.52 0.50 |
5. Resultados
6. Resultados e discussão
6.1. Desempenho dos classificadores
Os resultados dos experimentos de rotatividade são mostrados na Tabela 5. A Tabela 5 relata AUC, precisão e sensibilidade para uma instância de cada um dos três classificadores. As Figuras 3 e 4 mostram de forma semelhante as curvas ROC e as pontuações de AUC para estas experiências.
Em ambos os experimentos, esses classificadores mostraram poder preditivo imperfeito – mas mais poder preditivo do que uma estimativa aleatória (a linha de ‘passeio aleatório’ nas Figuras 3 e 4). As pontuações de precisão se aproximam de 70% nos melhores casos, o que significa que, na maioria dos casos, os classificadores de machine learning treinados em dados de ELDs preparados fazem previsões corretas de rotatividade. No entanto, as pontuações de sensibilidade são notavelmente baixas para todos os algoritmos em ambos os experimentos. As pontuações de recall mostradas na Tabela 5 mostram que cerca de metade dos motoristas que realmente rotacionaram foram classificados incorretamente pelos nossos algoritmos preditivos.
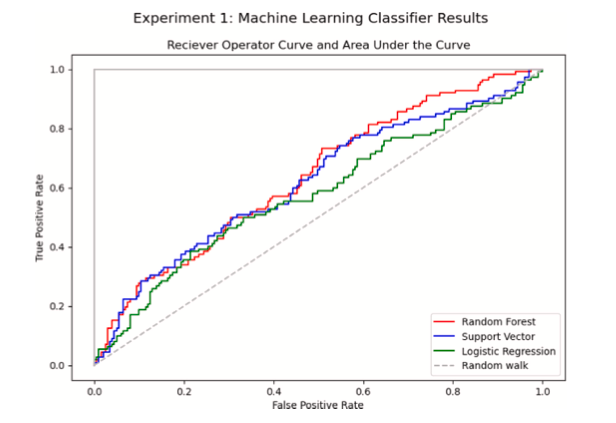
Fig. 3. Curva ROC para o Experimento 1.
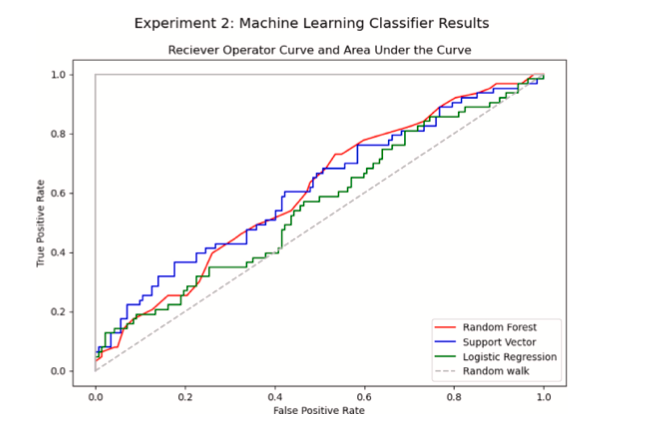
Fig. 4. Curva ROC para o Experimento 2.
6.2. Robustez dos resultados de precisão
Usando validação cruzada de 5 vezes, também testamos a robustez dessas descobertas. Esses resultados são geralmente consistentes na replicação. Os resultados de precisão agrupam-se ordenadamente em torno de 60 a 70% entre classificadores e experimentos. Os classificadores de florestas aleatórias e máquinas de vetores de suporte mostraram potencial para variação positiva atingindo 70 a 80%. Os resultados de sensibilidade mostram resultados igualmente consistentes, com pontuações agrupadas em torno de 50 a 60% entre algoritmos e experimentos. Os resultados de precisão e robustez da validação cruzada dos três classificadores foram comparados usando testes de Friedman, de acordo com a orientação de Demšar (2006). Em cada comparação de precisão e robustez experimental, a hipótese nula de tendência central não paramétrica equivalente não pôde ser rejeitada. Todos os três classificadores parecem ter tido um desempenho igualmente bom. Estes resultados são mostrados para cada classificador e cada experimento nas Figuras 5 e 6.
6.3. Importância do recurso post hoc
Para obter mais informações sobre o que os dados de ELDs preparados podem nos dizer sobre a rotatividade de motoristas de caminhão de longa distância, conduzimos uma análise post hoc da importância do recurso. Neste caso, isto significa compreender o papel que cada característica do dia da semana (média de horas e desvio padrão de horas) projetada a partir dos dados brutos dos ELDs desempenhou na previsão da rotatividade no nível do motorista. Isto é semelhante à abordagem em Davoodi et al. (2023). Em nosso contexto, entretanto, optamos por usar valores Shapley Additivie exPlanations (SHAP) ao comparar a importância do recurso. Os valores SHAP representam a contribuição aditiva exclusiva de cada recurso para a previsão do modelo (Baptista et al., 2022; Lee et al., 2023; Lundberg e Lee, 2017). Nas Figs. 7 e 8 mostramos o valor SHAP de cada recurso em cada experimento, para cada um dos três classificadores em ordem decrescente de importância por experimento e por classificador.
Vários padrões resultam da observação das Figuras 7 e 8. Primeiro, ao observar os principais preditores, os recursos baseados no tempo de condução geralmente têm classificação mais elevada do que os recursos baseados no tempo de espera. Ao considerar os 10 valores SHAP mais altos em recursos e experimentos, a condução domina em 4 dos 6 casos de classificador por experimento. Também podemos observar que os recursos baseados na média e no desvio padrão são importantes para fazer previsões. Em 4 dos 6 experimentos com classificadores, os 10 principais recursos incluíram uma combinação uniforme de ambos os tipos de medidas. Finalmente, os recursos baseados em dias de semana (segunda, terça, quarta e quinta-feira) dominam os recursos baseados em finais de semana (sábado e domingo) em todas as instâncias do classificador por experimento. No final, a quantidade e a consistência das horas de condução durante a semana de trabalho parecem ser as maiores responsáveis pelo poder preditivo do nosso modelo.
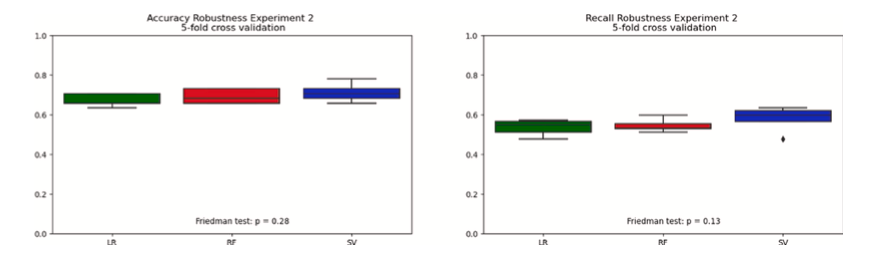
Fig. 5. Precisão no Experimento 1.
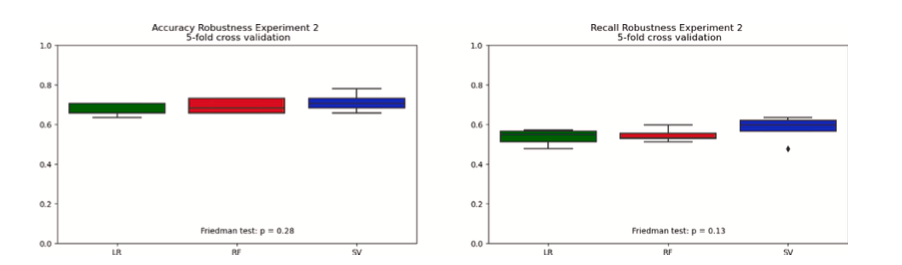
Fig. 6. Precisão no Experimento 2.
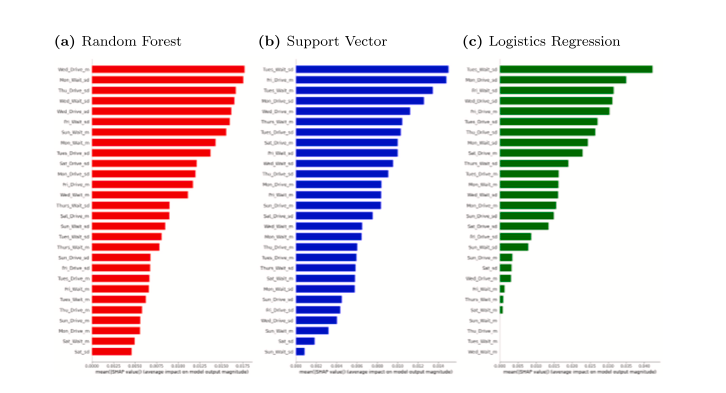
Fig. 7. Valores SHAP no Experimento 1.
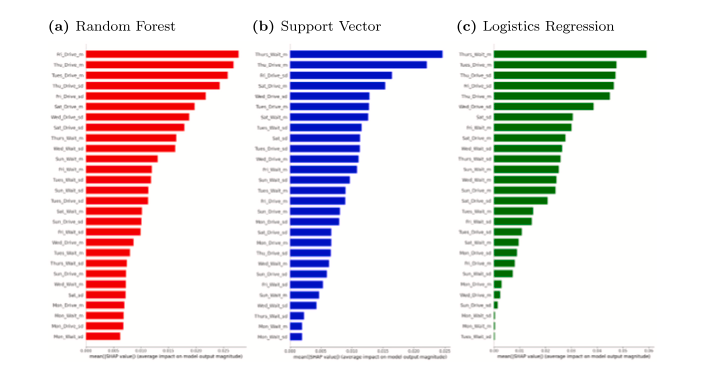
Fig. 8. Valores SHAP no Experimento 2.
8. Conclusões e trabalhos futuros
Este trabalho explora o potencial de uma nova fonte de dados, os Dispositivos de Registro Eletrônico, para prever eventos de rotatividade de motoristas. Para investigar esse potencial, preparamos dados brutos de ELDs fornecidos por uma empresa americana de transporte rodoviário de médio porte para aproximadamente 1.200 motoristas em dois experimentos diferentes. Organizamos os recursos com base no tempo gasto dirigindo e no tempo de espera por dia da semana. Consideramos a média e os desvios padrão de ambas as medidas. Aplicamos três classificadores aos dados preparados: regressão logística, florestas aleatórias e máquinas de vetores de suporte. Esses modelos mostraram precisão de 60 a 70% e sensibilidade de 50 a 60% nos dois experimentos e nos três classificadores. Na verdade, os dados ELD parecem ter um potencial anteriormente não reconhecido para prever a rotatividade individual de motoristas de caminhão quando utilizados desta forma com classificadores de machine learning supervisionados. Como a capacidade saudável de transporte rodoviário é fundamental para o funcionamento das cadeias de suprimentos modernas, propomos que estes resultados oferecem novas ferramentas técnicas, bem como insights para melhorar os problemas globais de retenção de caminhoneiros para o benefício das cadeias de suprimentos em todo o mundo.
Trabalhos futuros poderiam considerar a expansão desses insights em outros contextos. Os dados disponíveis para nossa equipe de pesquisa foram coletados apenas de motoristas americanos de caminhões de longa distância contratados. Embora estes condutores representem a grande maioria da escassez de caminhoneiros americanos (Association, 2022), não representam toda a comunidade global de caminhoneiros. Esperamos que essas descobertas sejam testadas quanto à generalização também em outros contextos.
REFERÊNCIAS
Akiba, T., Sano, S., Yanase, T., Ohta, T., & Koyama, M. (2019). Optuna: A next- generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining (pp. 2623–2631).
American Trucking Association, A. (2021). Driver short- age update 2021: Tech. rep., American Trucking Association, https://www.trucking.org.
Association, A. T. (2022). American trucking association driver short-age report: Tech. rep., American Trucking Association.
Baptista, M. L., Goebel, K., & Henriques, E. M. (2022). Relation between prognostics predictor evaluation metrics and local interpretability SHAP values. Artificial Intelligence, 306, Article 103667.
Belzer, M. H., & Sedo, S. A. (2018). Why do long distance truck drivers work extremely long hours? The Economic and Labour Relations Review, 29(1), 59–79.
Bertsimas, D., Allison, K., & Pulleyblank, W. R. (2016). The analytics edge. Dynamic Ideas LLC Charlestown, MA.
Bradley, A. P. (1997). The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition, 30(7), 1145–1159.
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Burks, S. V., & Monaco, K. (2019). Is the U.S. labor market for truck drivers broken.
Monthly Labor Review, 1–23.
Corsi, T. M., & Fanara, P., Jr. (1988). Driver management policies and motor carier
safety. Logistics and Transportation Review, 24(2), 153–163.
CSCMP (2022). CSCMP’s annual state of logistics report: Tech. rep., Council of Supply
Chain Management Professionals.
Cutler, A., Cutler, D. R., & Stevens, J. R. (2012). Random forests. In C. Zhang, & Y. Ma (Eds.), Ensemble machine learning: methods and applications. Springer.
Davoodi, S., Thanh, H. V., Wood, D. A., Mehrad, M., Rukavishnikov, V. S., & Dai, Z. (2023). Machine-learning predictions of solubility and residual trapping indexes of carbon dioxide from global geological storage sites. Expert Systems with Applications, 222, Article 119796.
De Croon, E. M., Sluiter, J. K., Blonk, R. W., Broersen, J. P., & Frings-Dresen, M. H.
(2004). Stressful work, psychological job strain, and turnover: a 2-year prospective
cohort study of truck drivers. Journal of Applied Psychology, 89(3), 442.
Demšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. The
Journal of Machine Learning Research, 7, 1–30.
FMCSA (2022). Summary of hours of service regulations. http://www.fmcsa.dot.gov/
regulations/hours- service/summary- hours- service- regulations.
FMCSA (2023). Federal motor carrier administration - electronic logging de- vices. from
https://eld.fmcsa.dot.gov/, Retrieved May 12, 2023.
Garver, M. S., Williams, Z., & Taylor, G. S. (2008). Employing latent class regression analysis to examine logistics theory: an application of truck driver retention. Journal of Business Logistics, 29(2), 233–257.
Hastie, T., Tibshirani, R., Friedman, J. H., & Friedman, J. H. (2009). The elements of statistical learning: data mining, inference, and prediction, Vol. 2. Springer.
Huang, Y., & Kechadi, T. (2013). An effective hybrid learning system for telecommunication churn prediction. Expert Systems with Applications, 40(14), 5635–5647.
Johnson, J. C., Bristow, D. N., McClure, D. J., & Schneider, K. C. (2011). Determinants of job satisfaction among long-distance truck drivers: An interview study in the United States. International Journal of Management, 28(1), 203.
Keller, S. B. (2002). Driver relationships with customers and driver turnover: key mediating variables affecting driver performance in the field. Journal of Business Logistics, 23(1), 39–64.
Khaitan, A., Mehlawat, M. K., Gupta, P., & Pedrycz, W. (2022). Socially aware fuzzy vehicle routing problem: A topic modeling based approach for driver well-being. Expert Systems with Applications, 205, Article 117655.
Lee, Y.-G., Oh, J.-Y., Kim, D., & Kim, G. (2023). SHAP value-based feature impor- tance analysis for short-term load forecasting. Journal of Electrical Engineering & Technology, 18(1), 579–588.
LeMay, S. A., Williams, Z., & Carver, M. (2009). A triadicic view of truck driver satisfaction. Journal of Transportation Management, 21(2), 1–15.
Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.), Advances in neural information processing systems, Vol. 30. Curran Associates, Inc., https://proceedings.neurips.cc/paper_files/ paper/2017/file/8a20a8621978632d76c43dfd28b67767- Paper.pdf.
Miller, J. W., Bolumole, Y., & Muir, W. A. (2021). Exploring longitudinal industry-level large truckload driver turnover. Journal of Business Logistics, 42(4), 428–450. Miller, J. W., Muir, W. A., Bolumole, Y., & Griffis, S. E. (2020). The effect of truckload driver turnover on truckload freight pricing. Journal of Business Logistics, 41(4), 294–309.
Miller, J. W., Saldanha, J. P., Hunt, C. S., & Mello, J. E. (2013). Combining formal controls to improve firm performance. Journal of Business Logistics, 34(4), 301–318. Min, H., & Lambert, T. (2002). Truck driver shortage revisited. Transportation Journal, 5–16.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12, 2825–2830.
Phares, J., & Balthrop, A. (2022). Investigating the role of competing wage oppor- tunities in truck driver occupational choice. Journal of Business Logistics, 43(2), 265–289.
Suzuki, Y., Crum, M. R., & Pautsch, G. R. (2009). Predicting truck driver turnover. Transportation Research Part E: Logistics and Transportation Review, 45(4), 538–550. Verbeke, W., Martens, D., Mues, C., & Baesens, B. (2011). Building comprehensible customer churn prediction models with advanced rule induction techniques. Expert Systems with Applications, 38(3), 2354–2364.
Williams, Z., Garver, M. S., & Stephen Taylor, G. (2011). Understanding truck driver need-based segments: creating a strategy for retention. Journal of Business Logistics, 32(2), 194–208.